
Since the release of DALL-E 2 at the end of 2022, prompt-based image generators are all the rage and many quality competitors are entering the market. But now we are already at the dawn of a new technology: the generation of videos by AI.
Last Tuesday, Google Research published a research paper on Lumiere, which can create highly realistic videos from text prompts and other images.
The model was designed to address an important challenge in video generation synthesis, namely creating “realistic, diverse, and coherent movements,” according to the article. You may have noticed that video generation models typically produce choppy videos, but Google’s approach provides a smoother viewing experience, as demonstrated in the video below.
This method of generating video differs from other existing models
Not only do the video clips look smooth, but they also look hyper-realistic, which is a huge improvement over other models. Lumiere achieves this through its Space-Time U-Net architecture, which generates the temporal duration of a video in one go.
This method of generating video differs from other existing models, which synthesize distant keyframes. According to the article, this approach inherently makes it difficult to keep the video consistent.
Lumiere can generate videos from different inputs, including text-to-video, which works like a regular image generator and generates a video from a text prompt, and image-to-video, which takes an image and uses the accompanying prompt to bring the photo to life in a video.
Competition with ImagenVideo, Pika, ZeroScope and Gen2
The template can also put a fun spin on video generation with styled generation, which uses a single reference frame to generate a video in the target style using a prompt from the user.
Besides generating videos, the template can be used to edit existing videos through various visual stylizations that modify a video to reflect a specific prompt, cinemagraphs that animate a specific area of a photo, and painting, which fills in the Missing or damaged areas of the video.
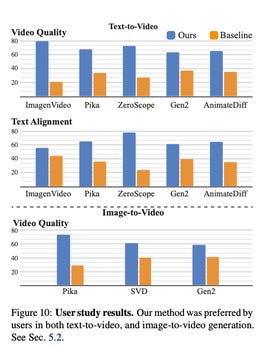
In its paper, Google measured Lumiere’s performance against other leading text-to-video delivery models, including ImagenVideo, Pika, ZeroScope, and Gen2, by asking a group of testers to select the video they judged the best in terms of visual quality and movement, without knowing which model had generated each video.
Lots of demos to get an idea
Google’s model outperformed others in every category, including text quality versus video, text alignment versus video, and image quality versus video.
Light
The model has not yet been made available to the general public; However, if you would like to learn more or watch the models in action, you can visit the Lumiere website, where you can see numerous demonstrations of the model performing the different tasks.
Source: “ZDNet.com”