
Tiernan Ray and Stability.ai’s Dream Studio
There you have it, you imagine the next step in your career: becoming an ace at prompting to avoid being swept away by the AI. Become a champion in the art of writing the best sentence to make a generative artificial intelligence program obey you, like OpenAI’s ChatGPT.
Not so fast: The art of prompts itself could be supported by automation using large language models (LLM).
In a paper published last week by Google’s DeepMind unit, researchers Chengrun Yang and his team created a program called OPRO that allows LLMs to try different prompts until they find one that comes closest to solving a task. This is a way to automate the trial and error that a person would do while typing.
Using LLMs to state in natural language the ideal to achieve
The research paper, titled “Large Language Models as Optimizers” published on the arXiv pre-print server, details an experiment on how to “optimize” using a language model, i.e. that is, to make the program produce more and more precise responses, approaching an ideal state.
Yang and his team decided, instead of explicitly programming this ideal state, to use LLMs to state in natural language the ideal to be achieved. This allows the AI program to adapt to constantly changing optimization demands for different tasks.
As Yang and his coauthors write, the linguistic processing flexibility of large language models “offers a new opportunity for optimization: instead of formally defining the optimization problem and deriving the update step with a programmed solver, we describe the optimization problem in natural language, then ask the LLM to iteratively generate new solutions based on the problem description and previously found solutions.
The power of Meta-Prompt
At the heart of the OPRO program is an algorithm called “Meta-Prompt”. Meta-Prompt reviews previous prompts and evaluates their effectiveness in solving a given problem. It then generates several prompts that it can try to find the best one.
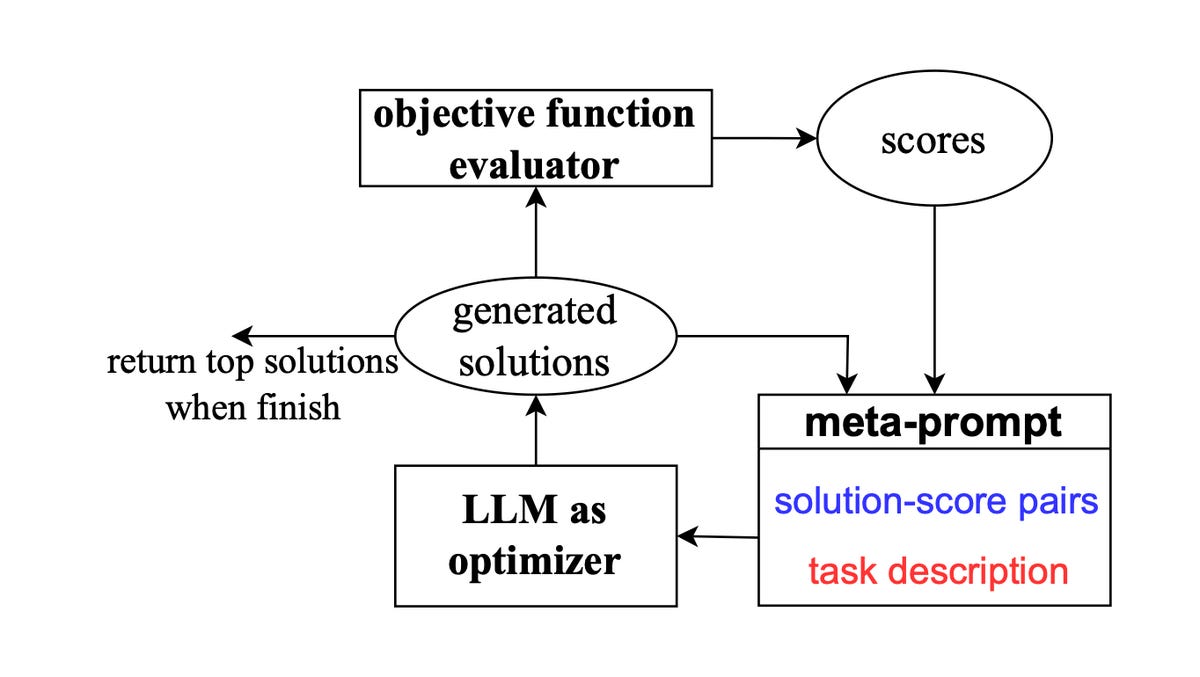
The structure of the DeepMind metaprompt. DeepMind
In fact, Meta-Prompt is like a person sitting at the keyboard, typing out lots of new possibilities based on what they’ve seen work and not work before. Meta-Prompt can be linked to any major language model to produce prompts and responses. The authors test a large number of different language models, including GPT-3 and GPT-4, as well as Google’s PaLM 2 language model.
The authors start by testing OPRO on basic problems. One of these is linear regression, in which the program is asked to “minimize a function”, that is, find a pair of numbers similar to earlier examples but producing a smaller numerical value like result.
Writing a good prompt for an LLM can be considered a task to optimize
The language model is therefore capable of finding solutions to a mathematical problem. This is despite the fact that solving this problem is normally tackled by a program designed for this problem alone – a “solver”, as it is called. As the authors write, “LLMs correctly capture optimization directions on small-scale problems simply based on the past optimization trajectory provided in the meta-prompt.”
And it turns out that the art of writing a good prompt for a large language model can itself be considered a task to be optimized.
Researchers have known this for some time. Microsoft scientists earlier this year proposed what they called “automatic prompt optimization.” This approach automatically modifies the writing of the prompt to improve it. Yang and his team went further. Instead of just modifying a previous prompt to improve it, Meta-Prompt generates entirely new prompts.
Benchmark with GSM8K and BIG-bench
As they explain, “each optimization step in our work generates new prompts that aim to increase test accuracy based on a trajectory of previously generated prompts, instead of modifying an input prompt in function of natural language feedback or to require that the new prompt follow the same semantic meaning.
And the researchers tested how well Meta-Prompt could optimize prompts.
They tested Meta-Prompt on benchmarks where optimizing the prompt was shown to improve performance.
One of them is “GSM8K” introduced in 2021 by OpenAI, a series of elementary school-level math problems such as “Nina bakes 4 dozen cookies in a week. If these cookies are shared equally among 16 people, how many of cookies does each person consume?
A second test is a derivative of BIG-bench, the reasoning test introduced last year by Google among others. Google’s authors’ new version, called BIG-bench Hard, introduced this year, focuses on reasoning problems where large language models have failed in the past to achieve human-level accuracy.
The magic phrase: “Let’s think step by step”
BIG-bench problems are “diverse,” as the Google authors wrote in the original article, “drawing problems from linguistics, mathematics, common sense reasoning, biology, physics , social bias, software development and other areas.
The authors compare their automatically generated prompts for both tasks to “hand-crafted” prompts, as illustrated in 2022 work by Takeshi Kojima and his team at the University of Tokyo and Google Research .
Kojima and his team found that they could improve the ability of large language models on tasks such as GSM8K and BIG-bench by simply adding the phrase “Let’s think step by step” at the start of the prompt, followed by a example answer. They found that this sentence was sufficient to induce “chain thinking” steps on the part of the language model.
With Meta-Prompt, Yang and his team find that they can automatically generate prompts with phrases similar to “Let’s think step by step,” but better – or more optimal, in their vernacular.

Example of a “meta-prompt” used to prompt the language model to offer more optimal messages. The orange text is the metaprompt, that is, the instructions that tell the language model how to construct a prompt. The blue text shows some examples. Purple text describes the optimization task and the output format. DeepMind
Optimize the algorithm that optimizes prompts
Sometimes automatically generated prompts become very complex. For example, in the BIG-bench reasoning task called “temporal_sequence”, a language model is provided with some elements of a scenario and is then asked to respond to the time something happened, For example :
Today Richard went to the swimming pool. What time could he have gone there?
We know that: Richard woke up at 7 o’clock. Samantha saw Richard walking in the garden from 7am to 8am.
Marc saw Richard working out at the gym from 8am to 9am.
David saw Richard going to class at school from 9am to 10am.
Andrew saw Richard waiting at the station from 10 a.m. to 4 p.m.
The swimming pool is closed after 5 p.m.
Between what hours could Richard have gone to the swimming pool?
Yang and his team found that Meta-prompt performed better because it compiled very complex questions such as the following:
“To determine the period of time a person was at a location, first identify all periods when the person was not seen doing anything else and the location was open. Then, eliminate any periods in which the person was seen doing something else. The remaining periods are possible periods in which the person could have been at that location.”
Overall, they found that “our optimized prompts significantly outperform human-designed prompts on GSM8K and Big-Bench Hard tests, sometimes by more than 50%.”
However, there is still work to be done to optimize the algorithm that optimizes the prompts.
Meta-Prompt is unable to extrapolate from negative examples
In particular, OPRO’s Meta-Prompt is not able to extrapolate from examples negative. “We tried to include error cases in Meta-Prompt rather than randomly sampling the training set at each optimization step,” they observe, “but the results are similar, indicating that the cases errors alone are not sufficiently informative for the LLM optimizer to understand the cause of the erroneous prediction.
Perhaps your next programming job will be to figure out the best way to trick Meta-Prompt into creating better prompts.
Source: “ZDNet.com”