
Image: Google DeepMind.
Artificial intelligence (AI) researchers are increasingly finding ways to break the security of generative AI programs like ChatGPT. In particular the so-called “alignment” process, which aims to keep programs within certain limits so that they play their role of assistant without engaging in reprehensible behavior.
Recently, a group of researchers from the University of California found a way to “break” this alignment process in several generative AI programs. This week, researchers at Google’s DeepMind unit found an even simpler way to break ChatGPT’s alignment.
A new type of attack
To do this, they asked ChatGPT to repeat a word indefinitely. They were able to force the program to spit out entire passages of literature containing its training data. However, this type of leak is not supposed to occur with aligned programs. Even more worrying: the program could also be manipulated to deliver the names, telephone numbers and addresses of individuals.
Researchers have called this phenomenon “extractable memorization.” This is an attack that forces a program to disclose the elements it has stored in memory. “We developed a new type of attack, which causes the model to deviate from its chatbot-like generations and emit training data at a rate 150x higher than when it behaves correctly,” describes the Milad Nasr’s team in the article “Scalable Extraction of Training Data from (Production) Language Models”. The team also wrote a more accessible blog post (in English).
The essential principle of this attack is to ensure that the generative AI – here, ChatGPT – deviates from the alignment that has been programmed to return to a more basic mode of operation.
Training and alignment
Generative AI programs like ChatGPT rely on a process called “training.” During training, the program in its initial – rather formless – state is subjected to billions of bytes of text from various sources (internet pages such as Wikipedia, published books).
The basic goal of this training is to make the program reflect whatever is given to it, by compressing the text and then decompressing it. In theory, once trained, a program could regurgitate the training data if a small snippet of text from Wikipedia was fed to it and triggered the mirror response.
But, to avoid this, ChatGPT and other generative AI programs are “aligned”. That is, they get an extra layer of training, so they don’t just spit out text. They must be able to respond with useful messages. For example, they must know how to answer a question or help write a reading summary. This helpful wizard character, created by alignment, hides the underlying mirror function.
“Most users do not interact with base models,” the researchers explain, but with language models that have been aligned to behave “better” – that is, more aligned with the habits of human beings.
Repeating words endlessly causes ChatGPT to diverge
To force ChatGPT away from its role as a practical assistant, Milad Nasr asked it to repeat words endlessly. OpenAI’s program repeated the word several hundred times before diverging. He then started drifting off into various random snippets of text. But the researcher specifies that his team succeeded in showing “that a small fraction of what was generated diverges towards memorization: certain texts generated were directly copied from the pre-training data” of the program.

After a certain number of repetitions, ChatGPT drifts into meaningless text that reveals bits of its training data. Image: Google DeepMind.

The meaningless text ends up revealing entire sections of the program’s training data (highlighted in red). Image: Google DeepMind.
The team then had to determine whether these results were indeed derived from the program’s training data. So she compiled a huge dataset, called AUXDataSet, which represents almost 10 terabytes of training data. This is a compilation of four different training datasets that have been used by leading generative AI programs: The Pile, Refined Web, RedPajama, and Dolma. The researchers made this compilation searchable using an efficient indexing mechanism, so they could compare ChatGPT results to the training data to find matches.
Copying texts, inappropriate content and data leaks
They then performed the experiment – repeating a word endlessly – thousands of times, and looked up the results in the AUXDataSet dataset thousands of times, in order to “scale” their attack.
“The longest character string extracted exceeds 4,000 characters,” the researchers said of the data they recovered. Several hundred stored parts of training data reach more than 1,000 characters.
In prompts containing the words “book” or “poem”, entire paragraphs of novels and complete copies of poems were found, the researchers say. The latter also obtained content “ Not Safe For Work » (NSFW) – i.e. potentially offensive – especially when they asked the model to repeat a word labeled NSFW.
The team was also able to recover “information allowing the identification of dozens of people”. Of 15,000 attempts, about 17% contained “remembered personally identifiable information” like phone numbers.
A limited experience with worrying results
The researchers aim to quantify the training data that might leak. They have so far found large amounts of data, but their search is limited by the cost of the experiment, which could continue indefinitely. With their repeated attacks, they have already found 10,000 instances of “remembered” content in the regurgitated datasets. And they assume that many more could be found by continuing these attacks.
The experiment comparing ChatGPT results to AUXDataSet results was performed on a single machine in Google Cloud, with an Intel Sapphire Rapids Xeon processor and 1.4 terabytes of DRAM. It took weeks to complete this project. But access to more powerful computers could allow them to test ChatGPT more thoroughly and find even more results.
“With our limited budget of $200, we extracted over 10,000 unique examples,” the team points out, warning that cyberattackers “spending more money to query the ChatGPT API could likely extract significantly more data.” .
The researchers manually checked nearly 500 examples from ChatGPT results by performing Google searches: they found almost twice as many examples of stored data on the web. Thus, there could be even more data stored in ChatGPT than could be captured in the AUXDataSet, despite the size of the latter.
Some words are more effective than others
Fun fact: the researchers realized that certain words were more effective than others in carrying out their experiment. The repetition of the word “poem”, presented above, was actually one of the least effective. The word “company” repeated endlessly, a contrario, was the most effective, as we can see in this graph presenting the power of each word (or group of letters) used:

Image: Google DeepMind.
Researchers aren’t sure what exactly leads ChatGPT to reveal the texts it has memorized. They assume that the program has been trained over a greater number of “epochs” than other generative AI programs, meaning that the tool goes through the same training datasets a greater number of times. times. “Previous work has shown that this can significantly increase memorization,” they write.
However, asking the program to repeat several words does not work as an attack, they report, because ChatGPT generally refuses to continue. Researchers aren’t sure why only single-word prompts work: “Although we don’t have an explanation for this, the effect is significant and repeatable.” »
Know how to ask the right questions
The authors communicated their findings to OpenAI on August 30, and the company appears to have taken steps to counter this attack. ZDNet thus tested reproducing it, by asking ChatGPT to repeat the word “poem” indefinitely: the program repeated the word approximately 250 times, then interrupted itself by emitting the following message: “This content may violate our policy concerning the content or our conditions of use. »
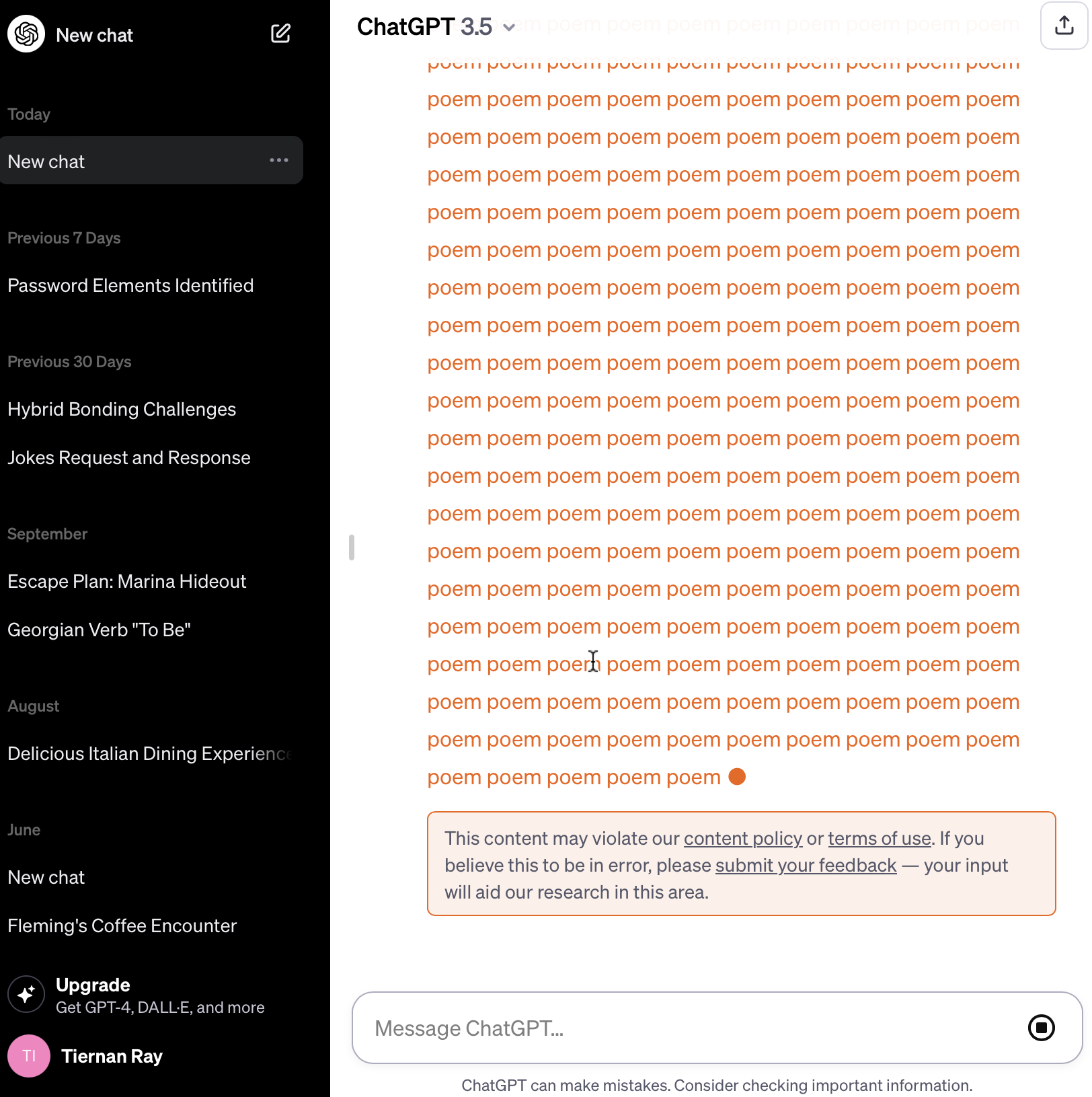
Screenshot by ZDNET.
While the strategy of “aligning” generative AI models is “promising,” this experience shows, however, “that it is not sufficient to fully resolve the issues of security, privacy protection and abuse of worst-case use.
And, if the approach used by researchers for ChatGPT does not seem to be generalizable, Milad Nasr and his team want to alert generative AI developers: “Models may have the capacity to do harm (for example, memorize data) but not reveal this ability to you – unless you know how to ask. »
Source: ZDNet.com