
- Google hat ein neues Tool eingeführt, mit dem Verlage das Training der KI-Modelle von Google ablehnen können.
- Immer mehr Top-Websites nutzen es.
- Allerdings wird Google nicht so stark blockiert wie OpenAI. Dafür kann es einen guten Grund geben.
Im Herzen des Webs gibt es ein großes Schnäppchen: Ein kleines Stück Code, das über Jahrzehnte für Ordnung gesorgt hat.
Mit Robots.txt können Websitebesitzer entscheiden, ob sie Google und andere Technologiegiganten ihre Online-Inhalte durchsuchen lassen möchten. Die meisten Websites haben Google dies überlassen, weil das Unternehmen so viel wertvollen Traffic verteilt.
Dann begannen die KI-Kriege. Es stellt sich heraus, dass all diese Inhalte in Datensätzen gespeichert wurden, die die Grundlage für das Training leistungsstarker KI-Modelle bilden, darunter solche von OpenAI, Google, Meta und anderen. Diese Modelle beantworten Benutzerfragen oft direkt, sodass möglicherweise weniger Verkehr verteilt wird und das große Web-Schnäppchen beginnt, sich aufzulösen.
Ein Teil der Reaktion von Google bestand darin, ein neues Tool auf den Markt zu bringen, mit dem Websites verhindern können, dass das Unternehmen ihre Inhalte zum Trainieren von KI-Modellen verwendet. Es heißt Google-Extended. Es kam im September heraus und erfreut sich zunehmender Beliebtheit.
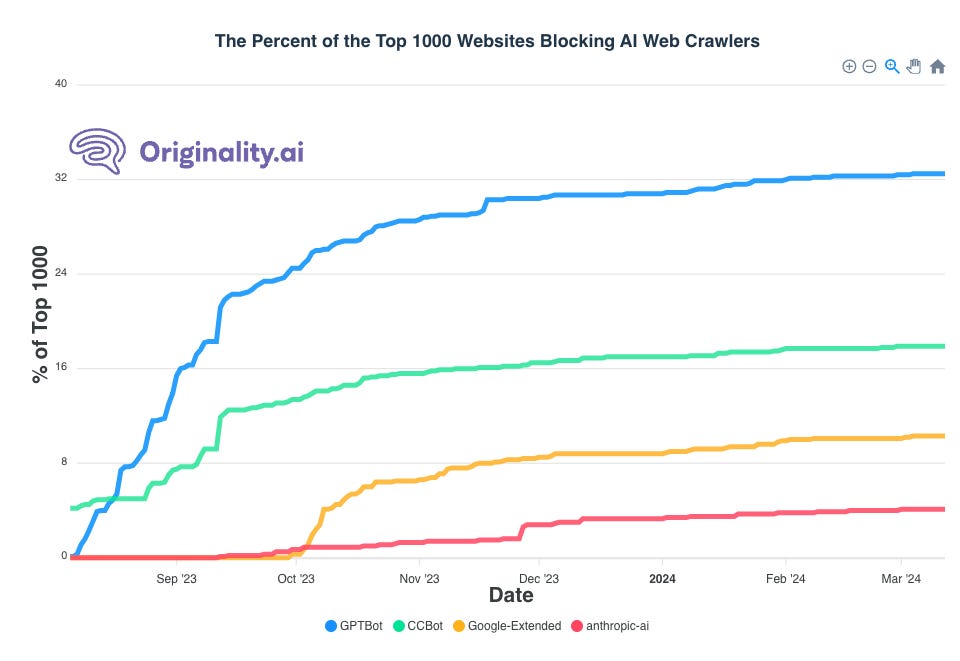
Daten geteilt von Originalität.ai zeigt, dass das Google-Extended-Snippet Ende März von etwa 10 % der Top-1.000-Websites verwendet wird.
Originalität.ai
Laut einer Rezension hat die New York Times den Google-Extended-Blocker aktiviert robots.txt-Datei. Die Veröffentlichung, die sich in einem hitzigen KI-Urheberrechtsstreit mit OpenAI befindet, hat auch den Zugriff dieses Startups auf seine Inhalte blockiert.
Es befindet sich auf einem Kriegspfad mit anderen Unternehmen, die entweder Online-Daten für das Training von KI-Modellen nutzen oder diese Art von Daten sammeln, damit andere sie auf ähnliche Weise nutzen können.
„Die Verwendung von Geräten, Tools oder Prozessen, die darauf ausgelegt sind, mithilfe automatisierter Mittel Daten zu extrahieren oder Inhalte zu extrahieren, ist ohne vorherige schriftliche Genehmigung verboten“, heißt es auf der Seite robots.txt von NYT.
Zu den verbotenen Verwendungen gehören „die Entwicklung jeglicher Software, maschinelles Lernen, künstliche Intelligenz (KI) und/oder große Sprachmodelle (LLMs)“, fügt der Herausgeber hinzu. Ein Sprecher von NYT lehnte eine Stellungnahme ab.
Google hat weniger blockiert als OpenAI
Für Google-Extended haben auch andere Websites dies aktiviert, darunter CNN, BBC, Yelp und Business Insider, der Herausgeber dieser Geschichte.
Allerdings hat Google-Extended deutlich weniger Anklang gefunden als der GPTBot von OpenAI, der sich auf rund 32 % der Top-1.000-Websites befindet. Auch CCBot, angeboten von Common Crawl, wurde stärker aktiviert.
BI fragte Jonathan Gillham, CEO von Originality.ai, warum Google-Extended weniger genutzt wird als andere KI-Trainingsdatenblocker.
Er sagte, wenn Google eine generative KI-Suchmaschine für die breite Öffentlichkeit einführt, bestehe das Risiko, dass Websites, die den Zugriff des Unternehmens auf Trainingsdaten blockiert haben, nicht in den KI-generierten Ergebnissen auftauchen.
„Wenn eine Frage lautet: ‚Was ist die beste Deep-Dish-Pizza in Chicago?‘ „Wenn ein Pizzaladen die KI von Google davon ausschließt, seine Website-Daten zum Trainieren zu nutzen, hat er keine Kenntnis von diesem Restaurant und kann es nicht in seine Antwort einbeziehen“, erklärte Gillham.
Google testet eine frühe Version der genAI-Suche über seine Search Generative Experience (SGE). Es ist unklar, ob das Unternehmen dies in Zukunft vollständig einführen wird oder wie sehr es sich von der herkömmlichen Google-Suchmaschine unterscheiden wird.
Diese Entscheidungen werden einen großen Beitrag zur Zukunft des Webs in dieser neuen KI-Welt leisten.
Axel Springer, die Muttergesellschaft von Business Insider, hat einen globalen Vertrag abgeschlossen, der es OpenAI ermöglicht, seine Modelle auf die Berichterstattung seiner Medienmarken zu trainieren.